'datetime' 컬럼은 object 타입 이기때문에 학습에 용이하게끔 하기위해 datetime 형태의 컬럼 'date' 를 만들어 줍니다
이후 다양한 과정을 통해 데이터를 정제해 줍니다
# date 컬럼을 바탕으로 함수를 이용해 기간에 맞는 데이터로 변경
def covid(date):
if str(date) < '2020-04-01':
return 'precovid'
elif str(date) < '2021-04-01':
return 'covid'
else:
return 'postcovid'
# 위의 함수를 바탕으로 covid 컬럼을 생성
bike_df['covid'] = bike_df['date'].apply(covid)
# month 컬럼을 바탕으로 함수를 이용해 지정한 변수에 맞는 데이터로 변경
winter = 12,1,2
spring = 3,4,5
summer = 6,7,8
fall = 9.10,11
def season(month):
if month in winter:
return 'winter'
elif month in spring:
return 'spring'
elif month in summer:
return 'summer'
elif month in fall:
return 'fall'
# 위의 함수를 바탕으로 season 컬럼을 생성
bike_df['season'] = bike_df['month'].apply(season)
# hour 컬럼을 바탕으로 함수를 이용해 지정한 변수에 맞는 데이터로 변경
night = 21,22,23,0,1,2,3,4
def day_night(hour):
if hour >= 5 and hour < 11:
return 'early morning'
elif hour >= 11 and hour < 13:
return 'late morning'
elif hour >= 13 and hour < 16:
return 'early afternoon'
elif hour >= 16 and hour < 17:
return 'late afternoon'
elif hour >= 17 and hour < 19:
return 'early evening'
elif hour >= 19 and hour < 21:
return 'late evening'
elif hour in night:
return 'night'
# 위의 함수를 바탕으로 day_night 컬럼을 생성
bike_df['day_night'] = bike_df['hour'].apply(day_night)
# 데이터 정제 후 기존의 컬럼들을 삭제
bike_df.drop(['datetime','month','date','hour'],axis=1, inplace=True)
bike_df.head()
# 원-핫-인코딩 진행
bike_df = pd.get_dummies(bike_df, columns=['weather_main','covid','season','day_night'])
bike_df.head()
학습을 하기 위해 회귀를 위한 함수를 import 해줍니다 이후 위에서 나누었던 데이터를 fit 을통해 학습 시켜준뒤 predict를 통해 나온 학습 결과값을 pred1의 변수에 넣어줍니다
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, pred1, squared=False)
이후 실제 결과와 학습 결과를 mean_squared_error를 통해 차이를 비교해 줍니다
3. 선형 회귀 vs 의사 결정 나무
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(X_train, y_train)
pred2 = lr.predict(X_test)
mean_squared_error(y_test, pred2, squared=False)
# 의사 결정 나무 : 222.90547303762153
# 선형 회귀 : 224.5257704711731
222.90547303762153 - 224.5257704711731
# 값이 적을 수록 좋음, 이 데이터에서는 의사 결정 나무가 더 좋은 모듈
이전에 배웠던 LinearRegression 과 비교해봐도 DecisionTreeRegressor 가 지금 현재 데이터에서는 더 적합한 모듈이라는 것을 알수 있습니다
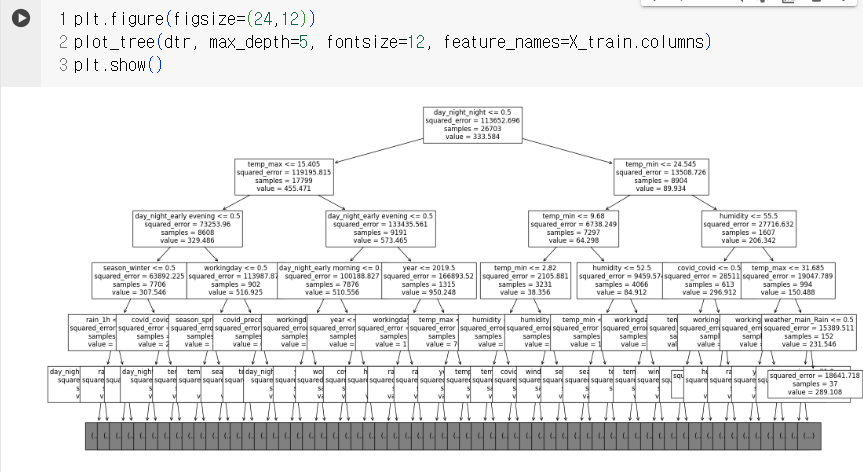
dtr = DecisionTreeRegressor(random_state=2023, max_depth=50, min_samples_leaf=30)
dtr.fit(X_train, y_train)
pred3 = dtr.predict(X_test)
mean_squared_error(y_test, pred3, squared=False)
# 의사 결정 나무 : 222.90547303762153
# 의사 결정나무(하이퍼 파라미터 튜닝) : 186.56448037541028
186.56448037541028 - 222.90547303762153
# 하이퍼 파라미터 튜닝을 통해 더 성능을 향상 시킨걸 볼 수 있음