# 데이터 프레임 형태로 불러오기
import pandas as pd
retail = pd.read_csv('/content/drive/MyDrive/데이터 분석/데이터/OnlineRetail.csv')
# 출력 row 갯수 설정
pd.options.display.max_rows = 6
retail
먼저 데이터 프레임 형태로 데이터를 불러옵니다
이때 출력되는 row 갯수를 6개로 설정해서 첫 3개, 마지막 3개가 출력될 수 있도록 해줍니다
데이터의 형태를 보면 541909개의 데이터와 8개의 컬럼으로 구성되어 있는걸 볼 수 있습니다
retail.info()
컬럼의 정보를 확인해 보면 데이터의 type과 컬럼명을 확인할 수 있습니다
주문 번호와 국가, 아이디가 나오는걸로 보아 사이트를 통해 상품을 구매한 내역과 구매자의 기본정보가 포함되어 있다는것을 알수 있습니다
# 각 컬럼당 null이 몇 개 있는지 확인
retail.isnull().sum()
이번에는 각 컬럼에 null이 몇 개 있는지 확인해 보았습니다
Description(상품 설명), Customer ID(고객 아이디)에서 null이 있는걸 확인해 볼 수 있습니다
# 비회원을 제거
retail = retail[pd.notnull(retail['CustomerID'])]
# 구입 수량이 1 이상인 데이터만 저장
retail = retail[retail['Quantity']>=1]
# 구입 가격이 1 이상인 데이터만 저장
retail = retail[retail['UnitPrice']>0]
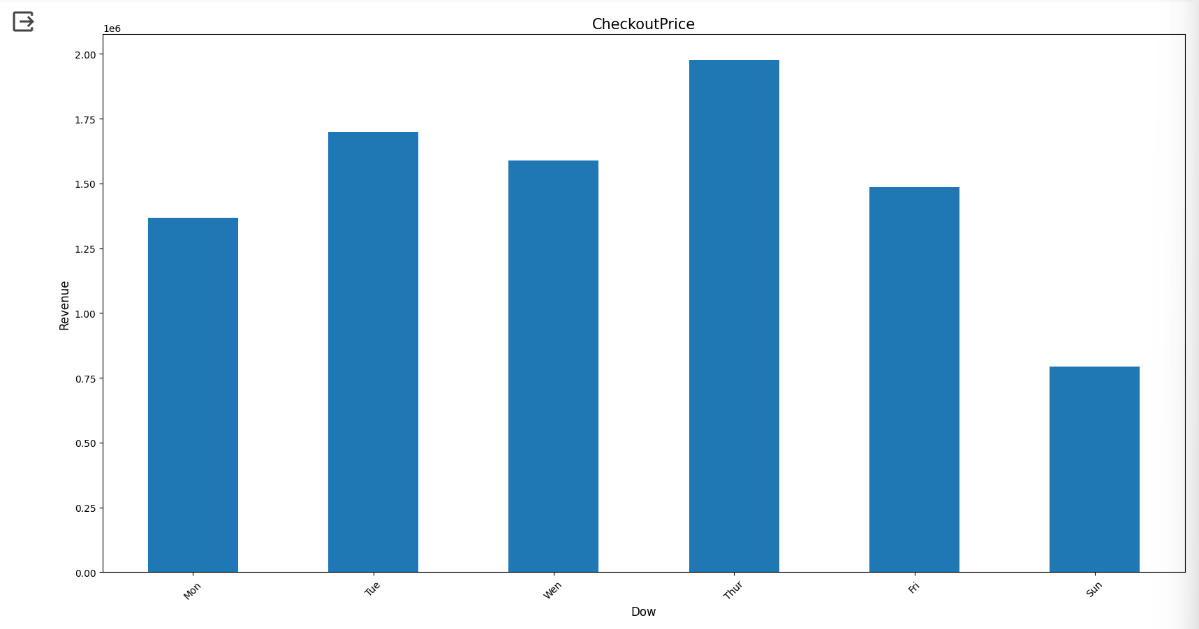
# 고객의 총 지출비용(CheckoutPrice) 파생변수 구하기
# 가격 * 수량
retail['CheckoutPrice'] = retail['UnitPrice'] * retail['Quantity']
retail
이번에는 다양한 과정을 통해 데이터를 정리해 보겠습니다
먼저 고객 아이디에 있던 null 값(비회원)을 제거합니다
그리고 Quantity(주문 수량)와 UnitPrice(상품 가격)이 1이상인 데이터만 저장합니다